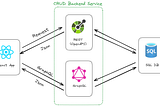
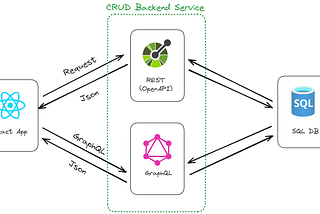
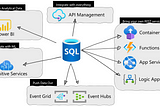
Davide MauriOpenAPI for your Azure SQL databaseYou don’t need to write your CRUD backend anymoreOct 26, 2023Oct 26, 2023
Davide MauriHow I built a session recommender in 1 hour using Open AIUsing a serverless, event-driven, fullstack architectureOct 18, 2023Oct 18, 2023
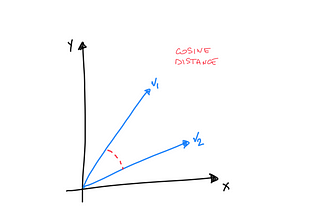
Davide MauriVector Similarity Search with Azure SQL database and OpenAIVector databases are gaining quite a lot of interest lately. Using text embeddings and vector operations makes extremely easy to find…Jun 4, 20233Jun 4, 20233
Davide MauriCTEs, Views or Temp Tables?I’ve just finished watching the video from the @GuyInACube about Common Table ExpressionsJan 20, 20233Jan 20, 20233
Davide MauriAdvent of Code — Day 10Last week I’ve been to the DevIntersection conference to present several sessions around Azure SQL and development (Modern Architecture…Dec 11, 2022Dec 11, 2022
Davide MauriAdvent of Code — Day 3Today’s Advent of Code challenge is really interesting. Somehow easy, but with a couple of interesting discussion points.Dec 5, 2022Dec 5, 2022
Davide MauriAdvent of Code — Day 4Day 4 — Camp Cleanup challenge is all about dealing with intervals. Intervals are trickier and more complex than one might think. No…Dec 5, 2022Dec 5, 2022
Davide MauriAdvent of Code — Day 2The second challenge of the Advent of Code 2022 is pretty straightforward with SQL. In summary the task is to use some starting values and…Dec 2, 2022Dec 2, 2022
Davide MauriAdvent of Code — Day 1The first challenge of the Advent of Code 2022 is out, and this year I decided to try to solve the proposed challenges only using T-SQL. I…Dec 1, 2022Dec 1, 2022
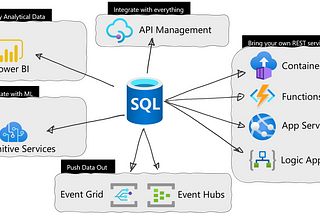
Davide MauriPush the data outApply event-driven architectures to the database tooNov 27, 2022Nov 27, 2022